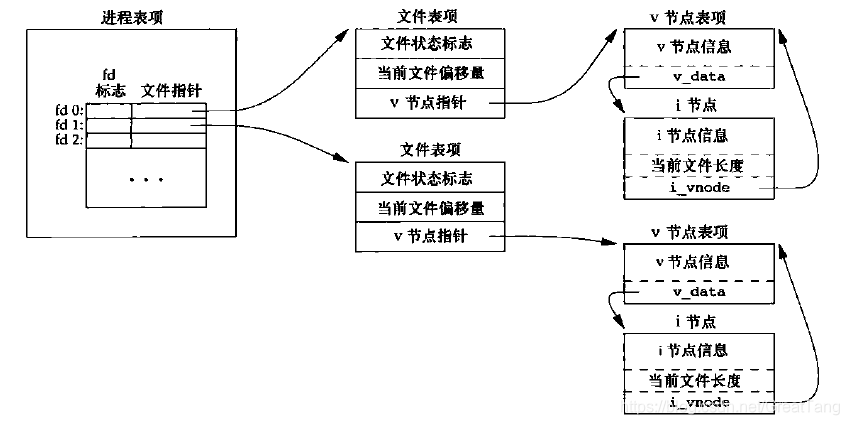
进程打开文件
struct task_struct(进程控制块)- 每个进程有一个
task_struct结构体,内核用它来描述进程。 - 里面有一个指针
files,执行该进程的files_struct。
- 每个进程有一个
1 | // https://elixir.bootlin.com/linux/v6.16/source/include/linux/sched.h |
files_struct(进程的文件表)- 这里保存了一个指向 fd 数组 的指针。
- fd 数组的下标就是 0, 1, 2…,每个元素指向一个
file *结构体。
1 | // https://elixir.bootlin.com/linux/v6.16/source/include/linux/fdtable.h |
struct file(打开文件表项)- 内核为每次
open()、pipe()、socket()创建一个struct file。 - 它记录了文件状态(读写偏移、flag、引用计数等)。
- 内核为每次
1 | // https://elixir.bootlin.com/linux/v6.16/source/include/linux/fs.h |
- inode / pipe / socket 内核对象
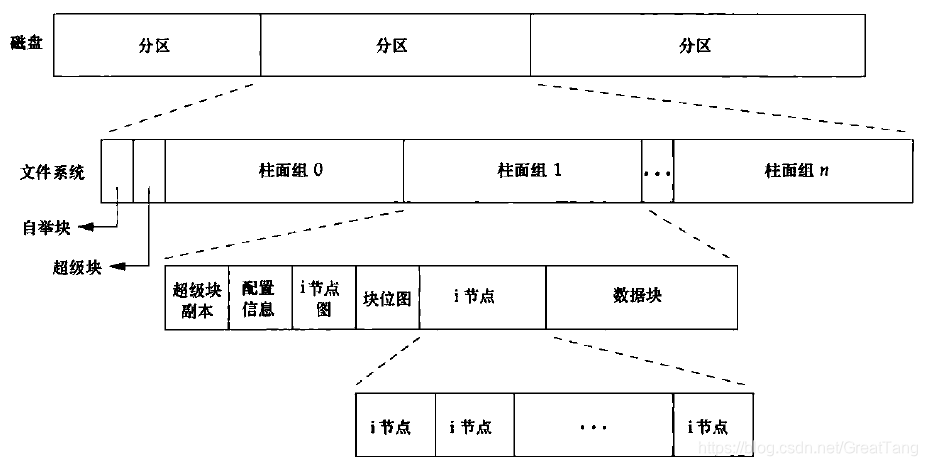
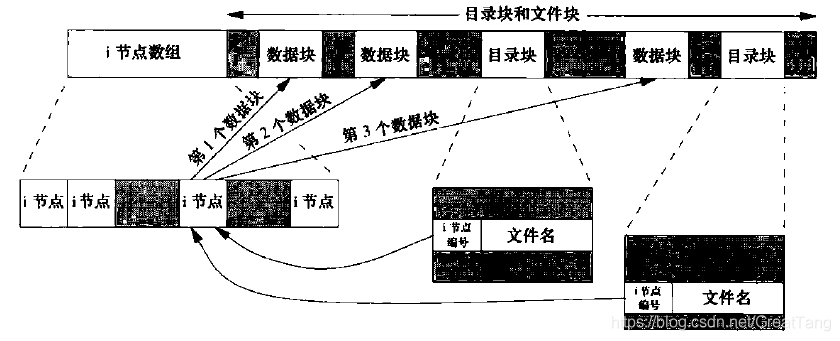
struct file再指向更底层的对象,比如 inode(磁盘文件)、socket 缓冲区、pipe 缓冲区。i-node 包含以下内容
- 链接计数(指向该i节点的目录项数);
- 文件类型、文件访问权限位、文件长度、指向文件数据块的指针等。
stat结构中的大多数信息都取自i节点。 - 只有两项重要数据放在目录项中:文件名和i-node编号。
软链接与硬链接
| 类型 | 定义 |
|---|---|
| 硬链接 (Hard Link) | 表示有多少目录项(文件名)指向同一个 inode 。它们指向同一个文件内容。 |
| 软链接 (Symbolic Link / Symlink) | 类似快捷方式,是一个 独立文件,内容是指向目标文件的路径。 |
- 硬链接:当硬链接数降为0时,才从磁盘的数据块中删除该文件,所以删除文件(即目录项)称为
unlink,而不是delete。 - 软链接:i-node中的文件类型是
S_IFLINK,表明是符号链接。
| 特性 | 硬链接 | 软链接 |
|---|---|---|
| 是否指向 inode | 是,直接指向同一 inode | 否,指向目标路径 |
| 是否可以跨文件系统 | 否,只能在同一分区 | 可以跨分区 |
| 是否可以链接目录 | 通常不能(除非 root) | 可以 |
| 删除目标文件后 | 文件内容仍可访问 | 链接会失效(称为“悬挂链接”) |
| 占用空间 | 不占用额外数据空间(只是多了一个目录项) | 占用少量空间存储路径信息 |
| 更新文件内容 | 所有硬链接同步可见 | 通过软链接修改目标文件内容时可见,软链接本身只是路径 |
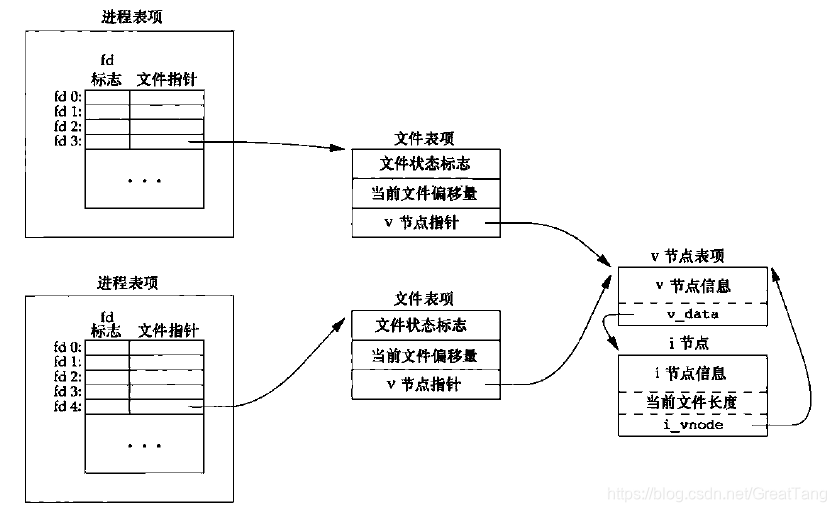
两个独立进程各自打开同一个文件
- O_APPEND:
- 原子操作:如果使用
O_APPEND标志打开一个文件,那么相应的标志也被设置到文件表项的文件状态标志中。每次对文件执行写操作时,文件表项中的当前文件偏移量首先会被设置为 i 节点表项中的文件长度(相对其他进程来说是原子操作,不论是两个独立的进程,还是父子进程)。这就使得每次写入的数据都追加到文件的当前尾端处。这里有一个测试的例子,文章结论不见得正确,请参考评论的讨论。 PIPE_BUF:只保证小于PIPE_BUF的内容是原子;如果大于则可能被多次多段写入。PIPE_BUF 是管道(pipe)单次写入保证原子的最大字节数,Linux 上是 4096 字节。
- 原子操作:如果使用
1 | # 查看 PIPE_BUF 大小 |
以下是 man 2 write 关于 O_APPEND 的说明:
If the file was open(2)ed with O_APPEND, the file offset is first set to the end of the file before writing. The adjustment of the file offset and the write operation are performed as an atomic step.
- lseek:
若一个文件用 lseek 定位到文件当前的尾端,则文件表项中的当前文件偏移量被设置为 i 节点表项中的当前文件长度(注意,此时,设置偏移量和写操作之间不是原子操作)。
dup()后的内核数据结构
dup() / dup2() 只复制 fd ,也就是在 fd 数组中新增了一个 fd 项。一般用来重定向。
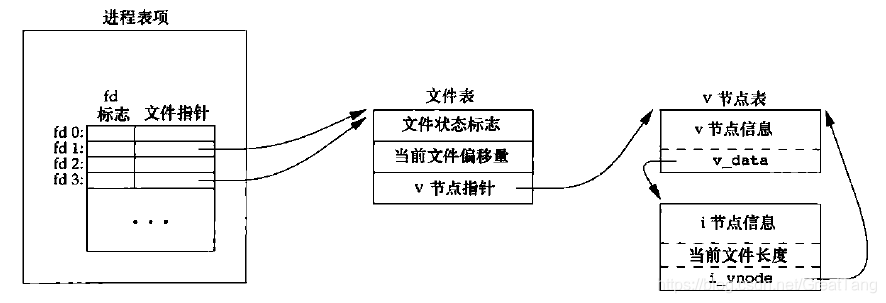
fork与文件共享
- 进程每打开一个文件,都会新建一个
struct file,并添加到 fd 数组或 fd 表中。- 对同一个文件,不同进程拥有各自的文件表项。
- 但是对每个文件,v节点表项在整个操作系统中只有一份。
fork()后的子进程直接复制父进程的 fd 数组,exec()也不能将其替换;- 子进程对
struct task_struct是深拷贝,所以 fd 数组被复制; - 但是子进程对 fd 数组是浅拷贝,fd 数组中的
struct file*仍然指向父进程创建的struct file(共享); - 所以子进程共享了文件状态标志 (O_APPEND, O_NONBLOCK, O_RDONLY 等)、当前文件偏移量。
- 子进程对
- 除非该文件描述符使用
fcntl()设置了FD_CLOEXEC标志,此时exec会关闭继承的文件描述符。
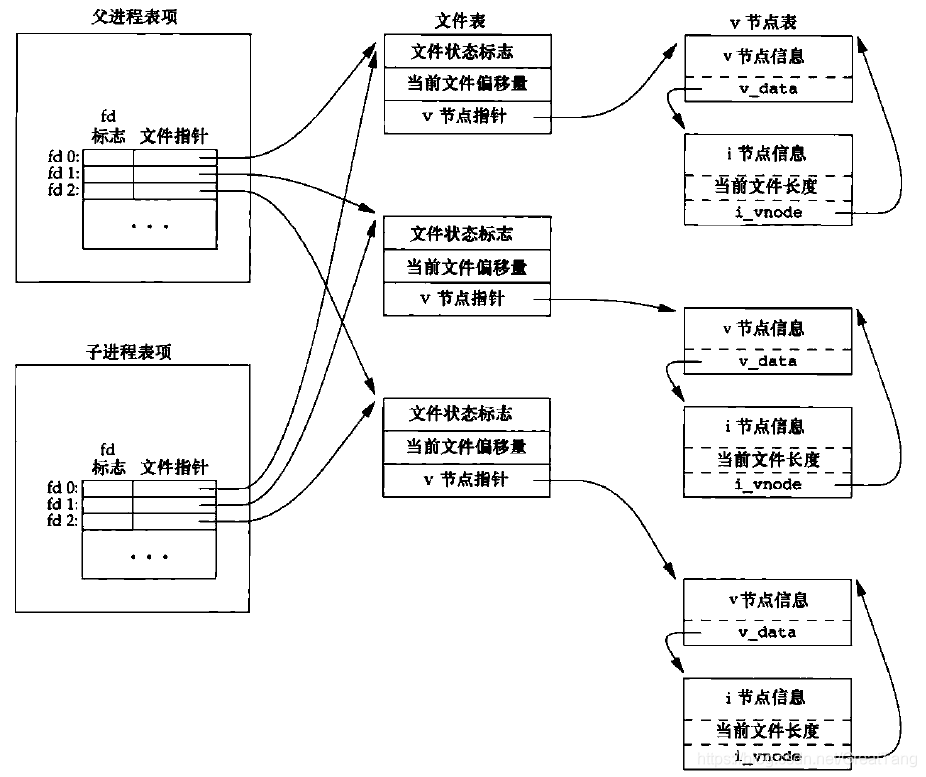
子进程对文件表项的修改,会不会影响父进程?
- shell进程启动时,会自动打开这三个文件描述符(可能由配置项决定);
- shell利用
fork()开启用户进程(子进程),该子进程复制父进程shell的所有文件描述符,于是0, 1, 2文件描述符被打开; - 由于子进程共享父进程的文件表项,子进程对文件状态标志(读、写、同步或非阻塞等)、文件偏移量的修改,将会影响父进程。
测试代码:
1 |
|
- 第一次运行:
1 | $ ./a.out |
- 第二次运行:
1 | $ ./a.out |
分析
- 第二次运行时,文件描述符0的初始状态保持了第一次运行的结果!
- 这是因为父进程shell的文件表项的文件状态标志被子进程
a.out改变了。
第三次运行:
重新启动shell,并运行
a.out
1 | $ ./a.out |
分析
- 第三次运行,结果与第一次一致,这说明我们的猜测正确。
- 父进程shell关闭之后,所有文件描述符被关闭,文件IO被关闭,文件表被释放。重启shell也就重置了文件表。
引申:
在此我们注意到,文件描述符0, 1, 2(标准输入、标准输出、标准错误)在一个shell及其所有子进程中,对应的文件(设备)是同一个。由于共享了文件表项,指向了同一个v-node表项,故都指向同一个虚拟终端。这与我们的平时观察一致,不然shell运行程序时,输入输出的入口在哪里呢?
如果进程打开文件,此时我们使用 rm / unlink 删除文件,会发生什么?
什么也不会发生。因为 Linux 文件系统的设计允许文件名(目录项)和文件内容(inode)分离。只有当所有引用(包括文件描述符和内存映射)都关闭后,inode 才会被删除。
在 Linux 中,一个文件由三部分组成:
- 目录项(filename):比如
/lib/libexample.so - inode(元数据):记录权限、大小、时间戳等
- 数据块(内容):实际的文件内容
rm 只是删除了目录项(文件名),并没有删除 inode 或数据块,只要还有进程引用它。
引用 inode 的方式包括:
- 打开文件(open())
- 映射文件(mmap())
- 动态链接器加载 .so 文件
这些引用会让内核知道:这个 inode 仍然在使用中,不能释放。
这是为了支持非常重要的行为:
✅ 允许进程继续使用已打开或已映射的文件,即使文件名被删除。
这在很多场景下非常有用:
- 日志轮转:删除旧日志文件,进程仍在写入
- 安全性:防止其他进程访问文件名,但当前进程仍可使用
- 临时文件:创建后立即删除,只让当前进程使用
在 Linux 内核中,每个 inode 结构体有一个字段 i_count,表示该 inode 当前被引用的次数。这个引用包括:
- 被文件系统挂载
- 被进程打开
- 被内核缓存使用
这个字段不是用户空间可以直接查看的,但你可以通过以下方式间接观察:
| 方法 | 能看到什么 |
|---|---|
ls -li |
inode 号 + 硬链接引用计数 |
lsof -p <PID> | grep / fuser </path/to/so> |
是否有进程打开文件 |
/proc/<PID>/fd/ |
查看文件描述符引用 |
/proc/<PID>/maps |
查看映射 |
ldd |
查看可执行文件依赖的 .so |
strace |
跟踪运行时加载行为 |
内核字段 i_count |
真实引用计数(需内核调试) |
在本地文件系统(如 ext4)中:
- 即使文件正在使用,
rm也能删除目录项 - 文件内容仍保留在 inode 中,直到所有引用关闭
但在 NFS 文件系统 中:
- 客户端不能立即删除正在被使用的文件
- 所以它会将文件重命名为
.nfsXXXX - 等引用释放后,自动删除该临时文件
所以此时如果 rm -rf 目录,但是目录下某文件被使用,会提示 xxx/.nfs000000004ec2d5e70000da89 。
1 | $ lsof -p <PID> | grep .nfs |
因为 so 被手动删除,此时引用的 so 被重命名成 .nfsXXXX 。
手动删除 .so 文件后,系统生成了 .nfsXXXX 文件,但进程仍然能继续使用它。进程怎么知道新文件名?
答案是:进程根本不知道新文件名,也不需要知道。
当一个进程打开一个文件(比如 libexample.so),它获得的是一个 文件描述符(fd),这个描述符指向的是内核中的 inode,而不是文件名。
那 .nfsXXXX 文件名是给谁看的?
它是 NFS 客户端自动创建的临时文件名,用于:
- 保留 inode 内容,直到所有引用关闭
- 让系统知道这个文件还不能真正删除
- 让你可以用 lsof 或 fuser 查找谁在使用它
📌 这个文件名不会被通知给进程,也不会影响进程的运行。
正常情况下:进程关闭后 .nfsXXXX 自动消失
- .nfsXXXX 文件是由 NFS客户端 创建的临时文件
- 当某个文件被打开后删除,客户端会将其重命名为 .nfsXXXX
- 一旦该文件的 打开引用计数为 0(即所有进程都关闭了该文件),客户端会自动删除 .nfsXXXX
⚠️ 异常情况:文件可能残留
如果出现以下情况,.nfsXXXX 文件可能不会自动删除:
- 客户端 crash 或断网,未能完成清理动作
- 使用 kill -9 强制终止进程,绕过了正常关闭流程
- NFS 客户端或服务器之间同步延迟
- 文件被多个进程同时打开,只有部分进程关闭
在这些情况下,.nfsXXXX 文件会残留在文件系统中,直到手动清理。
管道
通过上文的叙述,我们很容易想到管道本质上也是一种特殊的文件,所以管道机制之所以可以进程间通信也是根据共享文件表项保证的。
管道和文件进行进程间通信的本质相同。
Linux 文件锁与记录锁
TODO
参考
- 《UNIX 环境高级编程》
- 《Linux 内核设计与实现(原书第 3 版) - Linux Kernel Development, Third Edition》,(美)拉芙(Love, R.)著;陈莉君,康华译. ——北京:机械工业出版社,2011.9(2021.5 重印)
- 图解进程控制块stask_struct